Tableaux de données avec Pandas#

À faire
Mystification
Manipulation de données#
Nous allons apprendre à manipuler des données, c’est-à-dire une table avec en colonne des attributs et en ligne des instances en python.
Bibliothèque Pandas#
Pandas est une bibliothèque python qui permet de:
manipuler des tableaux de données et,
faire des analyses statistiques
comme on pourrait le faire avec un tableur (excel par exemple), mais programmatiquement, donc permettant l”automatisation.
Les tables de données (type DataFrame): sont des tableaux à deux (ou plus)
dimensions, avec des étiquettes (labels) sur les lignes et les colonnes. Les données ne
sont pas forcément homogènes: d’une colonne à l’autre, le type des données peut
changer (chaînes de caractères, flottants, entiers, etc.); de plus certaines données
peuvent être manquantes.
Les séries (type Series) sont des tables à une seule dimension (des vecteurs),
typiquement obtenues en extrayant une colonne d’un DataFrame.
Dans ce cours, par tableau, on entendra un tableau à deux dimensions de type
DataFrame, tandis que par série on entendra un tableau à une dimension de type
Series.
On retrouve ces concepts de DataFrame et de Series dans les autres bibliothèques ou
systèmes d’analyse de données comme R.
De plus, Pandas permet de traiter des données massives réparties sur de très nombreux ordinateurs en s’appuyant sur des bibliothèques de parallélisme comme dask
Séries de données#
Nous devons commencer par importer la bibliothèque pandas; il est traditionnel de
définir un raccourci pd:
import pandas as pd
Construisons une série de températures:
temperatures = pd.Series([8.3, 10.5, 4.4, 2.9, 5.7, 11.1], name="Température")
temperatures
0 8.3
1 10.5
2 4.4
3 2.9
4 5.7
5 11.1
Name: Température, dtype: float64
Vous noterez que la série est considérée comme une colonne et que les indices de ses
lignes sont affichés. Par défaut, ce sont les entiers \(0,1,\ldots\), mais d’autres indices
sont possibles. Comme pour les tableaux C++ ou les listes Python, on utiliser la notation
“t[i]” pour extraire la ligne d’indice i:
temperatures[3]
np.float64(2.9)
La taille de la série s’obtient de manière traditionnelle avec Python avec la fonction
len:
len(temperatures)
6
Calculons la moyenne des températures à l’aide de la méthode mean:
temperatures.mean()
np.float64(7.1499999999999995)
Calculez la température maximale à l’aide de la méthode max:
### BEGIN SOLUTION
temperatures.max()
### END SOLUTION
np.float64(11.1)
Calculez la température minimale:
### BEGIN SOLUTION
temperatures.min()
### END SOLUTION
np.float64(2.9)
Quelle est la gamme de données (le range en anglais) de température ?
### BEGIN SOLUTION
temperatures.max() - temperatures.min()
### END SOLUTION
np.float64(8.2)
Tableaux de données (DataFrame)#
Nous allons maintenant construire un tableau contenant les données d’acidité de l’eau de plusieurs puits. Il aura deux colonnes: l’une pour le nom des puits et l’autre pour la valeur du pH (l’acidité).
Nous pouvons maintenant construire le tableau à partir de la liste des noms des puits et la liste des pH des puits:
df = pd.DataFrame({
"Noms" : ['P1', 'P2', 'P3', 'P4', 'P5', 'P6', 'P7', 'P8', 'P9', 'P10'],
"pH" : [ 7.0, 6.5, 6.8, 7.1, 8.0, 7.0, 7.1, 6.8, 7.1, 7.1 ]
})
df
| Noms | pH | |
|---|---|---|
| 0 | P1 | 7.0 |
| 1 | P2 | 6.5 |
| 2 | P3 | 6.8 |
| 3 | P4 | 7.1 |
| 4 | P5 | 8.0 |
| 5 | P6 | 7.0 |
| 6 | P7 | 7.1 |
| 7 | P8 | 6.8 |
| 8 | P9 | 7.1 |
| 9 | P10 | 7.1 |
Vous remarquerez que:
Il est traditionnel de nommer
df(pourDataFrame) la variable contenant le tableau. Mais il est souhaitable d’utiliser un meilleur nom chaque fois que naturel!La première colonne du tableau donne l’index des lignes. Par défaut, il s’agit de leur numéro, commençant à 0, en plus des colonnes « Noms » et « pH ».
Ce tableau à deux dimensions est vu comme une collection de colonnes. De ce fait,
df[label] extrait la colonne d’étiquette label, sous la forme d’une série:
df['Noms']
0 P1
1 P2
2 P3
3 P4
4 P5
5 P6
6 P7
7 P8
8 P9
9 P10
Name: Noms, dtype: object
Vous pouvez ensuite accéder à chacune des valeurs du tableau en en précisant le label de sa colonne puis l’indice de sa ligne. Voici le nom dans la deuxième ligne (indice 1):
df['Noms'][1]
'P2'
Et la valeur du pH dans la quatrième ligne (indice 3):
df['pH'][3]
np.float64(7.1)
Là encore, vous remarquerez que l’accès est de la forme df[colonne][ligne] alors
qu’avec un tableau C++ l’accès serait de la forme t[ligne][colonne].
Métadonnées et statistiques#
Nous utilisons maintenant Pandas pour extraire quelques métadonnées et statistiques de
nos données.
D’abord la taille du tableau:
df.shape
(10, 2)
Le titre des colonnes:
df.columns
Index(['Noms', 'pH'], dtype='object')
Le nombre de lignes:
len(df)
10
Des informations générales:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Noms 10 non-null object
1 pH 10 non-null float64
dtypes: float64(1), object(1)
memory usage: 292.0+ bytes
La moyenne de chaque colonne pour laquelle cela fait du sens, c’est-à-dire seulement les colonnes contenant des valeurs numériques (ici que le pH):
df.mean(numeric_only = True)
pH 7.05
dtype: float64
Les écarts-types:
df.std(numeric_only = True)
pH 0.38658
dtype: float64
La mediane:
df.median(numeric_only = True)
pH 7.05
dtype: float64
Le quantile 25%:
df.quantile(.25, numeric_only=True)
pH 6.85
Name: 0.25, dtype: float64
Les valeurs min et max:
df.min()
Noms P1
pH 6.5
dtype: object
df.max()
Noms P9
pH 8.0
dtype: object
Un résumé des statistiques principales:
df.describe()
| pH | |
|---|---|
| count | 10.00000 |
| mean | 7.05000 |
| std | 0.38658 |
| min | 6.50000 |
| 25% | 6.85000 |
| 50% | 7.05000 |
| 75% | 7.10000 |
| max | 8.00000 |
L’indice du pH max:
df['pH'].idxmax()
4
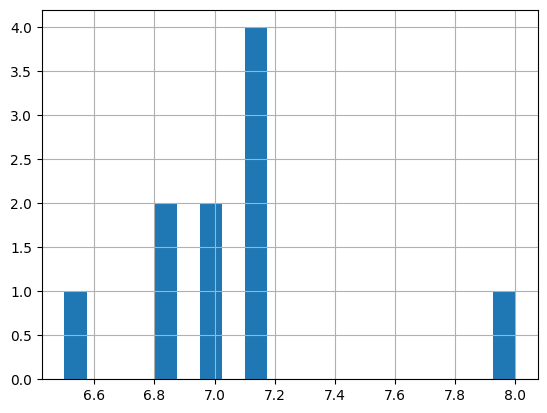
Un histogramme des pH. Remarque : Ici, on a l’option bins = 20, cela veut dire qu’on divise le range des pH (l’axe des x) en 20 groupes de meme taille. Changez la valeur de bins à 2 et regardez la différence:
df['pH'].hist(bins=20);
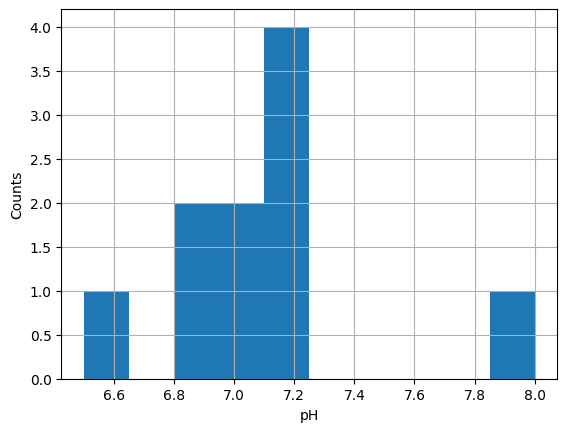
Avec pyplot, il est possible de peaufiner le résultat en ajoutant des labels aux axes, etc:
import matplotlib.pyplot as plt
df['pH'].plot(kind='hist')
plt.grid()
plt.ylabel('Counts')
plt.xlabel('pH');
Opérations de bases de données#
Pandas permet de faire des opérations de bases de données (pour ceux qui ont fait le projet Données Libres, souvenez-vous de «select», «group by», «join», etc.). Nous ne montrons ici que la sélection de lignes; vous jouerez avec «group by» plus loin.
Transformons le tableau pour que l’une des colonnes serve d’indices; ici nous nous servirons des noms:
df1 = df.set_index('Noms')
df1
| pH | |
|---|---|
| Noms | |
| P1 | 7.0 |
| P2 | 6.5 |
| P3 | 6.8 |
| P4 | 7.1 |
| P5 | 8.0 |
| P6 | 7.0 |
| P7 | 7.1 |
| P8 | 6.8 |
| P9 | 7.1 |
| P10 | 7.1 |
Il est maintenant possible d’accéder à une valeur de pH en utilisant directement le nom comme index de ligne:
df1['pH']['P1']
np.float64(7.0)
Sélectionnons maintenant toutes les lignes de pH \(7.1\):
df1[df1['pH'] == 7.1]
| pH | |
|---|---|
| Noms | |
| P4 | 7.1 |
| P7 | 7.1 |
| P9 | 7.1 |
| P10 | 7.1 |
Comment cela fonctionne-t-il?
Notons pH la colonne de même label:
pH = df1['pH']
pH
Noms
P1 7.0
P2 6.5
P3 6.8
P4 7.1
P5 8.0
P6 7.0
P7 7.1
P8 6.8
P9 7.1
P10 7.1
Name: pH, dtype: float64
Comme avec NumPy, toutes les opérations sont vectorisées sur tous les éléments du
tableau ou de la séries. Ainsi, si l’on écrit pH + 1 (ce qui n’a pas de sens
mathématique, les objets étant de type très différents: pH est une série tandis que 1
est un nombre), cela ajoute 1 à toutes les valeurs de la série:
pH + 1
Noms
P1 8.0
P2 7.5
P3 7.8
P4 8.1
P5 9.0
P6 8.0
P7 8.1
P8 7.8
P9 8.1
P10 8.1
Name: pH, dtype: float64
De manière similaire, si l’on écrit pH == 7.1, cela renvoie une série de booléens,
chacun indiquant si la valeur correspondante est égale ou non à \(7.1\):
pH == 7.1
Noms
P1 False
P2 False
P3 False
P4 True
P5 False
P6 False
P7 True
P8 False
P9 True
P10 True
Name: pH, dtype: bool
Enfin, si l’on indexe un tableau par une série de booléen, cela extrait les lignes pour
lesquelles la série contient True:
df1[pH == 7.1]
| pH | |
|---|---|
| Noms | |
| P4 | 7.1 |
| P7 | 7.1 |
| P9 | 7.1 |
| P10 | 7.1 |
Exercice: les notes#
Les notes d’Info 111 (anonymes!) de l’an dernier sont dans le fichier CSV notes_info_111.csv. Consultez le contenu de ce fichier: vous noterez que les valeurs sont séparées par des virgules “,” (CSV: Comma Separated Value).
Voici comment charger ce fichier comme tableau Pandas:
df = pd.read_csv("data/notes_info_111.csv", sep=",")
Affichez en les statistiques simples:
### BEGIN SOLUTION
df.describe()
### END SOLUTION
| Total de Examen mi-semestre (EE) (Brut) | projet (CCTP) (Brut) | Note enseignant (Brut) | Outil externe Contrôle 1 PLaTon, jeudi 21 et vendredi 22 octobre (Brut) | Outil externe Contrôle 2 PLaTon, jeudi 9 - vendredi 10 décembre (Brut) | Total de Contrôles PLaTon (Brut) | Total de Note de TD (CCE) (Brut) | Total de Examen final (EEF) (Brut) | Total du cours (Brut) | |
|---|---|---|---|---|---|---|---|---|---|
| count | 276.000000 | 266.000000 | 272.000000 | 267.000000 | 267.000000 | 285.000000 | 286.000000 | 273.000000 | 286.000000 |
| mean | 13.715942 | 15.308271 | 15.978309 | 16.972846 | 17.319663 | 16.088035 | 15.631049 | 12.463004 | 13.420420 |
| std | 4.448350 | 4.625492 | 3.465690 | 4.306431 | 3.996111 | 5.528698 | 4.366991 | 5.763870 | 4.828153 |
| min | 0.600000 | 0.000000 | 5.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.200000 | 0.000000 |
| 25% | 10.400000 | 13.000000 | 14.000000 | 16.150000 | 16.560000 | 15.260000 | 14.085000 | 7.800000 | 9.997500 |
| 50% | 14.000000 | 17.000000 | 16.550000 | 18.850000 | 19.060000 | 18.490000 | 16.915000 | 13.200000 | 14.395000 |
| 75% | 17.800000 | 19.000000 | 18.000000 | 19.620000 | 19.690000 | 19.530000 | 18.497500 | 18.000000 | 17.537500 |
| max | 20.000000 | 20.000000 | 20.000000 | 20.000000 | 20.000000 | 20.000000 | 20.000000 | 20.000000 | 20.000000 |
Avec DataGrid, vous pouvez explorer interactivement le tableau; faites quelques essais:
de filtrage (icône );
de tri (cliquer sur le titre de la colonne par rapport à laquelle trier).
todo
verifier datagrid pour l’an prochain
from ipydatagrid import DataGrid
DataGrid(df)
Exercice: Les prénoms#
Dans cet exercice il s’agit d’analyser une base de données qui porte sur les prénoms
donnés à Paris entre 2004 et 2018 (souvenirs du S1?). Ces données sont librement
accessibles également sur le site
opendata de la ville de
Paris. La commande shell suivante va les télécharger dans le fichier
liste_des_prenoms.csv s’il n’est pas déjà présent.
if [ ! -f liste_des_prenoms.csv ]; then
curl --http1.1 "https://opendata.paris.fr/explore/dataset/liste_des_prenoms/download/?format=csv&timezone=Europe/Berlin&lang=fr&use_labels_for_header=true&csv_separator=%3B" -o data/liste_des_prenoms.csv
fi
Ouvrez le fichier pour consulter son contenu.
En vous inspirant de l’exemple ci-dessus, importez le fichier
data/liste_des_prenoms.csvdans un tableauprenoms. Indication : le fichier utilise des points-virgules;comme séparateurs et non des virgules,.
### BEGIN SOLUTION
prenoms = pd.read_csv('data/liste_des_prenoms.csv', sep=';')
### END SOLUTION
Si le test ci-dessous ne passe pas, vérifiez que vous avez bien appelé votre tableau
prenoms (sans accent, avec un s):
assert isinstance(prenoms, pd.DataFrame)
assert list(prenoms.columns) == ['Nombre prénoms déclarés', 'Sexe', 'Annee', 'Prenoms','Nombre total cumule par annee']
Affichez les dix premières lignes du fichier. Indication: consulter la documentation de la méthode
headavecprenoms.head?
### BEGIN SOLUTION
prenoms.head(10)
### END SOLUTION
| Nombre prénoms déclarés | Sexe | Annee | Prenoms | Nombre total cumule par annee | |
|---|---|---|---|---|---|
| 0 | 179 | M | 2024 | Isaac | 179 |
| 1 | 125 | M | 2024 | Paul | 125 |
| 2 | 83 | F | 2024 | Lina | 83 |
| 3 | 78 | F | 2024 | Victoria | 78 |
| 4 | 77 | M | 2024 | Aylan | 77 |
| 5 | 68 | M | 2024 | Zayn | 68 |
| 6 | 61 | F | 2024 | Inaya | 61 |
| 7 | 60 | F | 2024 | Mariam | 60 |
| 8 | 55 | F | 2024 | Inès | 55 |
| 9 | 48 | M | 2024 | Orso | 48 |
Affichez les lignes correspondant à votre prénom (ou un autre prénom tel que Mohammed, Maxime ou encore Brune si votre prénom n’est pas dans la liste):
### BEGIN SOLUTION
prenoms[prenoms.Prenoms == "Brune"]
### END SOLUTION
| Nombre prénoms déclarés | Sexe | Annee | Prenoms | Nombre total cumule par annee | |
|---|---|---|---|---|---|
| 655 | 7 | F | 2006 | Brune | 7 |
| 712 | 11 | F | 2007 | Brune | 11 |
| 1037 | 20 | F | 2010 | Brune | 20 |
| 2785 | 25 | F | 2015 | Brune | 25 |
| 3601 | 53 | F | 2018 | Brune | 53 |
| 3771 | 26 | F | 2016 | Brune | 26 |
| 3869 | 50 | F | 2019 | Brune | 50 |
| 7527 | 42 | F | 2021 | Brune | 42 |
| 8048 | 44 | F | 2020 | Brune | 44 |
| 14110 | 27 | F | 2012 | Brune | 27 |
| 14246 | 23 | F | 2014 | Brune | 23 |
| 14918 | 20 | F | 2011 | Brune | 20 |
| 15955 | 6 | F | 2004 | Brune | 6 |
| 17181 | 26 | F | 2017 | Brune | 26 |
| 20948 | 18 | F | 2013 | Brune | 18 |
| 21774 | 16 | F | 2008 | Brune | 16 |
| 22038 | 10 | F | 2005 | Brune | 10 |
| 22830 | 18 | F | 2009 | Brune | 18 |
| 23317 | 55 | F | 2022 | Brune | 55 |
| 25488 | 40 | F | 2023 | Brune | 40 |
| 26008 | 42 | F | 2024 | Brune | 42 |
Faites de même interactivement avec
DataGrid:
DataGrid(prenoms)
Extraire dans une variable
prenoms_femmesles prénoms de femmes (avec répétitions), sous la forme d’une série. Indication: retrouvez dans les exemples ci-dessus comment sélectionner des lignes et comment extraire une colonne.
### BEGIN SOLUTION
prenoms_femmes = prenoms['Prenoms'][prenoms['Sexe'] == 'F']
prenoms_femmes
### END SOLUTION
2 Lina
3 Victoria
6 Inaya
7 Mariam
8 Inès
...
26669 Saskia
26672 Edmée
26673 Enola
26674 Gala
26675 Perla
Name: Prenoms, Length: 13583, dtype: object
Combien y en a-t’il?
### BEGIN SOLUTION
len(prenoms_femmes)
### END SOLUTION
13583
# Vérifie que prenoms_femmes est bien une série
assert isinstance(prenoms_femmes, pd.Series)
# Vérifie le premier prénom alphabetiquement
assert prenoms_femmes.min() == 'Aaliyah'
# Vérifie le nombre de prénoms après suppression des répétitions
assert len(set(prenoms_femmes)) == 1491
Procédez de même pour les prénoms d’hommes :
### BEGIN SOLUTION
prenoms_hommes = prenoms['Prenoms'][prenoms['Sexe']=='M']
prenoms_hommes
### END SOLUTION
0 Isaac
1 Paul
4 Aylan
5 Zayn
9 Orso
...
26666 Nahel
26670 Aharon
26671 Theo
26676 Marlo
26677 Viggo
Name: Prenoms, Length: 13095, dtype: object
### BEGIN SOLUTION
len(prenoms_hommes)
### END SOLUTION
13095
Une petite vérification:
assert len(prenoms_hommes) + len(prenoms_femmes) == len(prenoms)
Exercice : Transformez les Prenoms en majuscule de la table prenoms. Affectez le
résultat à la variable prenoms_maj
Objectif: savoir rechercher dans la documentation pandas: https://pandas.pydata.org/docs/user_guide/.
### BEGIN SOLUTION
# Solution apres avoir cherche dans "working with text" in the user guide
prenoms_maj = prenoms['Prenoms'].str.upper()
### END SOLUTION
Exercice \(\clubsuit\)
Quel est le prénom le plus déclaré, en cumulé sur toutes les années? Affectez le à la
variable prenom.
Indication: consulter le premier exemple à la fin de la documentation de la méthode
groupby pour calculer les nombres cumulés par prénom (avec sum). Puis utilisez
DataGrid pour visualiser le résultat et le trier, ou bien utilisez sort_values, ou
idxmax.
### BEGIN SOLUTION
df = prenoms.groupby('Prenoms').sum()
# Solution 1
DataGrid(df)
# Solution 2
df.sort_values("Nombre prénoms déclarés")
### END SOLUTION
| Nombre prénoms déclarés | Sexe | Annee | Nombre total cumule par annee | |
|---|---|---|---|---|
| Prenoms | ||||
| Rubens | 5 | M | 2004 | 5 |
| Said | 5 | M | 2015 | 5 |
| Sahel | 5 | M | 2016 | 5 |
| Safya | 5 | F | 2015 | 5 |
| Sabine | 5 | F | 2005 | 5 |
| ... | ... | ... | ... | ... |
| Arthur | 5235 | MMMMMMMMMMMMMMMMMMMMM | 42294 | 5235 |
| Louise | 5373 | FFFFFFFFFFFFFFFFFFFFF | 42294 | 5373 |
| Adam | 5857 | MMMMMMMMMMMMMMMMMMMMM | 42294 | 5857 |
| Raphaël | 5887 | MMMMMMMMMMMMMMMMMMMMM | 42294 | 5887 |
| Gabriel | 7087 | MMMMMMMMMMMMMMMMMMMMM | 42294 | 7087 |
2823 rows × 4 columns
### BEGIN SOLUTION
# Solution 3
prenom = df['Nombre prénoms déclarés'].idxmax()
### END SOLUTION
Ce test vérifie que vous avez trouvé la bonne réponse; sans vous la donner; la magie des fonctions de hachage :-)
import hashlib
assert hashlib.md5(prenom.encode("utf-8")).hexdigest() == 'b70e2a0d855b4dc7b1ea34a8a9d10305'
Conclusion#
À faire
qu’est-ce qui a été vu dans cette feuille?